Chenyou Fan and David Crandall
Lifelogging cameras capture everyday life from a first-person perspective, but generate so much data that it is hard for users to browse and organize their image collections effectively. In this paper, we propose to use automatic image captioning algorithms to generate textual representations of these collections. We develop and explore novel techniques based on deep learning to generate captions for both individual images and image streams, using temporal consistency constraints to create summaries that are both more compact and less noisy.
We evaluate our techniques with quantitative and qualitative results, and apply captioning to an image retrieval application for finding potentially private images. Our results suggest that our automatic captioning algorithms, while imperfect, may work well enough to help users manage lifelogging photo collections. An expanded version of this paper is available here.

Figure 1: Sample captions generated by captioning technique with diversity regulation.
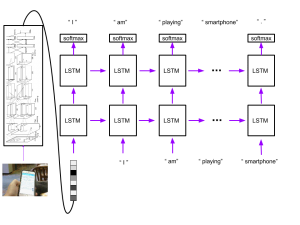
Figure 2: LSTM model for generating captions
[papersandpresentations proj=egovision:deepdiary]
Downloads
- Poster.
- Github Code Repository This repository is caffe implementation of image captioning on lifelogging data. Please check our paper and repository readme for more information of how to use this package on generating interesting and diverse sentences for your own photos.
- Lifelogging dataset This dataset contains the image VGG features and human labeling we collected during this project. Our github site has a detailed explanation of how to use the data files to train a human labeling model.
- AMT dataset We list a subset of our dataset with photos which we published on Amazon Mechanical Turk for public labeling.
Acknowledgements
 |
 |
|
|||
| National Science Foundation |
Nvidia | Lilly Endowment | IU Pervasive Technology Institute | IU Vice Provost for Research |