Md Alimoor Reza and David Crandall
Modern electronic devices consist of a wide range of integrated circuits (ICs) from various manufacturers. Ensuring that an electronic device functions correctly requires verifying that its ICs and other component parts are correct and legitimate. Towards this goal, we investigate using machine learning and computer vision to identify and verify integrated circuit packages using visual features alone. We propose a deep metric learning approach to learn a feature embedding to capture important visual features of the external packages of ICs. We explore several variations of Siamese networks for this task and learn an embedding using a joint loss function. To evaluate our approach, we collected and manually annotated a large dataset of 6,387 IC images, and tested our embedding on three challenging tasks:(1) fine-grained retrieval, (2) fine-grained IC recognition, and (3)verification. We believe this to be among the first papers targeting the novel application of fine-grained IC visual recognition and retrieval, and hope it establishes baselines to advance research in this area.

We propose to learn deep embeddings from images of integrated circuits to retrieve, recognize, and verify them. Some instances from our dataset are shown.
Paper
BibTeX
@inproceedings{reza_aipr20,
author={Reza, Md Alimoor and Crandall, David J.},
booktitle={2020 IEEE Applied Imagery Pattern Recognition Workshop (AIPR)},
title={IC-ChipNet: Deep Embedding Learning for Fine-grained Retrieval, Recognition, and Verification of Microelectronic Images},
year={2020}}
Architecture
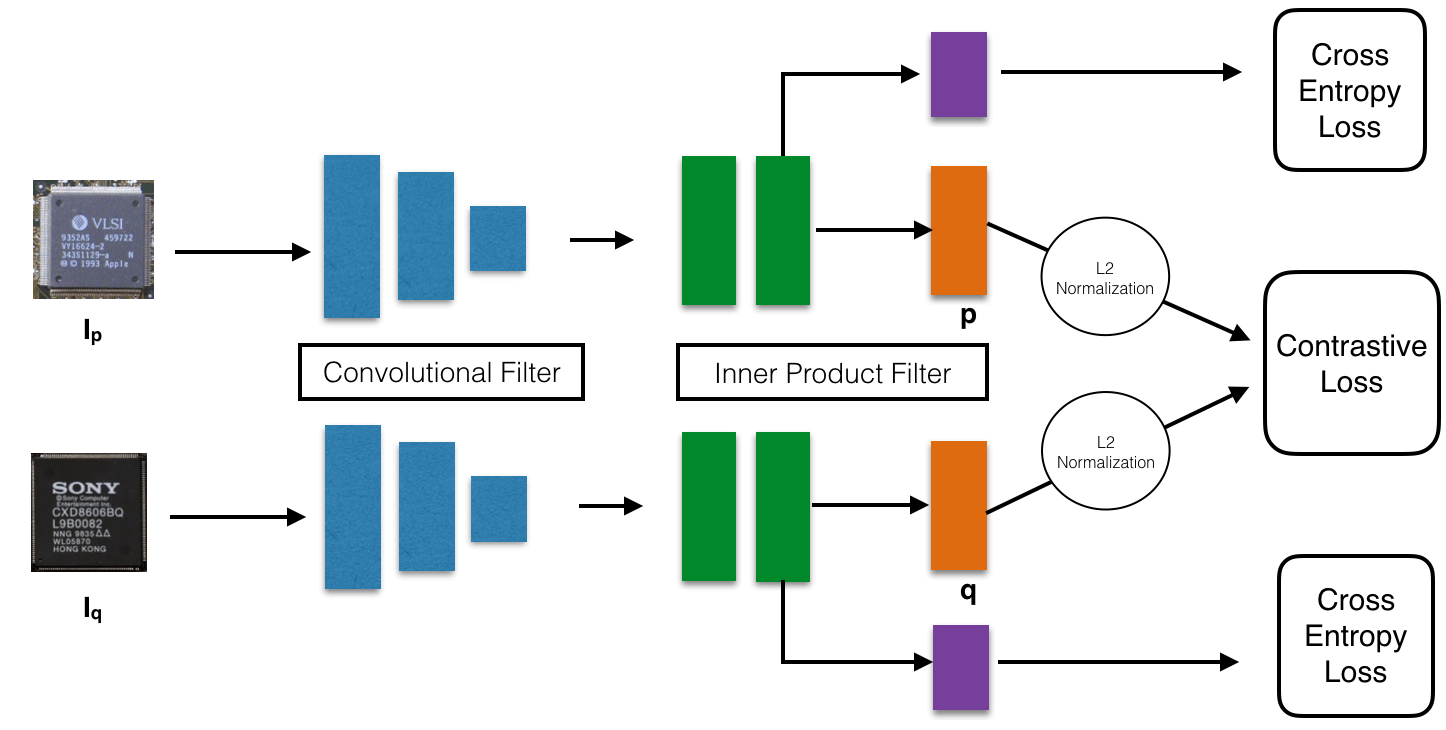
IC-ChipNet architectural layout. Pairs of images are fed through the convolutional filters (shared weights) to extract feature maps in blue. These feature maps go through the inner-product layer (shared weights) to reach a latent representation(orange). A combination of contrastive and cross-entropy loss allows us to learn the embedding from a large number of input images.
Resources
Dataset
We partitioned our dataset of 6,387 images into 70% training images, 10% validation images, and 20% test images (see Table I in the paper for details).
- Training/validation/test images: Download
- Text files containing the image names according to different splits: Download
- IC chip class labels to names mapping: Download
Code
- Training and inference code: TBA
- Our trained models: TBA
Acknowledgements
This research was funded by the Indiana Innovation Institute (IN3). We also would like to thank the following IndianaUniversity undergraduate students for assisting us in image collection and annotation: Kristopher Jung, Yongming Fan, Zunaeed Salahuddin, John Kaefer, Tiancong Zhao, and He He.