Authors: Satoshi Tsutsui and David Crandall.
Abstract
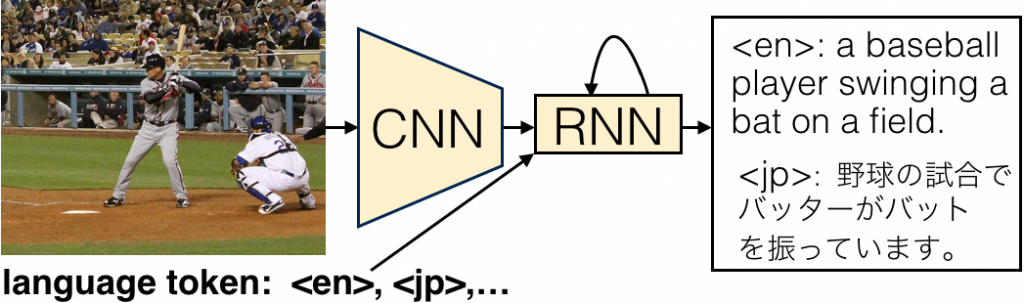
Recent work in computer vision has yielded impressive results in automatically describing images with natural language. Most of these systems generate captions in a sin- gle language, requiring multiple language-specific models to build a multilingual captioning system. We propose a very simple technique to build a single unified model across languages, using artificial tokens to control the language, making the captioning system more compact. We evaluate our approach on generating English and Japanese captions, and show that a typical neural captioning architecture is capable of learning a single model that can switch between two different languages.
Resources
– Github code: https://github.com/apple2373/chainer-caption
– Arxiv of the paper: https://arxiv.org/abs/1706.0627
– Citation: If you use the figure separator in your research or found it useful, please consider to cite:
@article{multilingual-caption-arxiv,
title={{Using Artificial Tokens to Control Languages for Multilingual Image Caption Generation}},
author={Satoshi Tsutsui, David Crandall},
journal={arXiv:1706.06275},
year={2017}
}
@inproceedings{multilingual-caption,
author={Satoshi Tsutsui, David Crandall},
booktitle = {CVPR Language and Vision Workshop},
title = {{Using Artificial Tokens to Control Languages for Multilingual Image Caption Generation}},
year = {2017}
}
Examples
Randomly selected samples of automatically-generated image captions. En only captions are from the model trained on English, Jp only are from the model trained on Japanese, and Unified are from the single model trained with both.
