Stefan Lee, Haipeng Zhang, and David Crandall
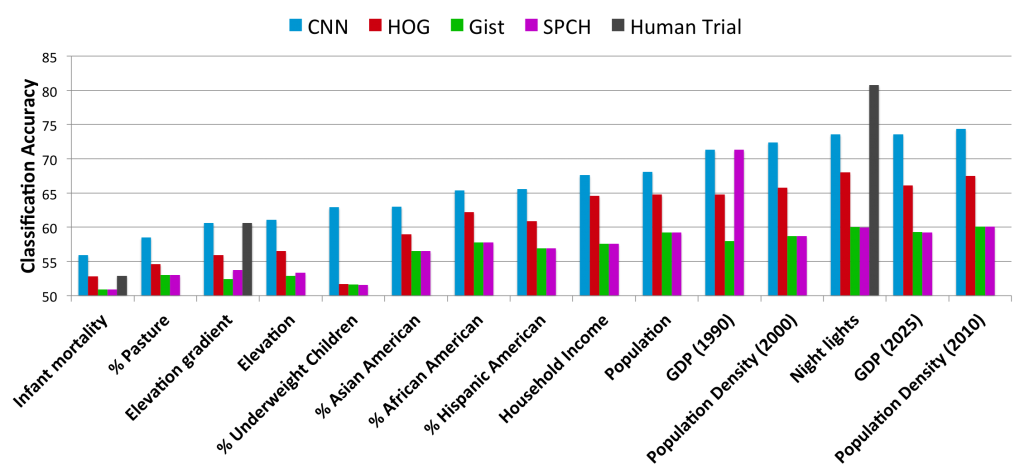
Geographic location is a powerful property for organizing large-scale photo collections, but only a small fraction of online photos are geo-tagged. Most work in automatically estimating geo-tags from image content is based on comparison against models of buildings or landmarks, or on matching to large reference collections of geotagged images. These approaches work well for frequently photographed places like major cities and tourist destinations, but fail for photos taken in sparsely photographed places where few reference photos exist. Here we consider how to recognize general geo-informative attributes of a photo, e.g. the elevation gradient, population density, demographics, etc. of where it was taken, instead of trying to estimate a precise geo-tag. We learn models for these attributes using a large (noisy) set of geo-tagged images from Flickr by training deep convolutional neural networks (CNNs). We evaluate on over a dozen attributes, showing that while automatically recognizing some attributes is very difficult, others can be automatically estimated with about the same accuracy as a human.
Results
[papersandpresentations proj=socialmining:geoattributes]
Download
Code and data avaliable soon!