HOPE-Net: A Graph-based Model
for Hand-Object Pose Estimation
Bardia Doosti, Shujon Naha, Majid Mirbagheri, David Crandall
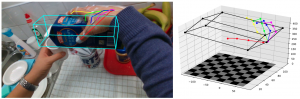
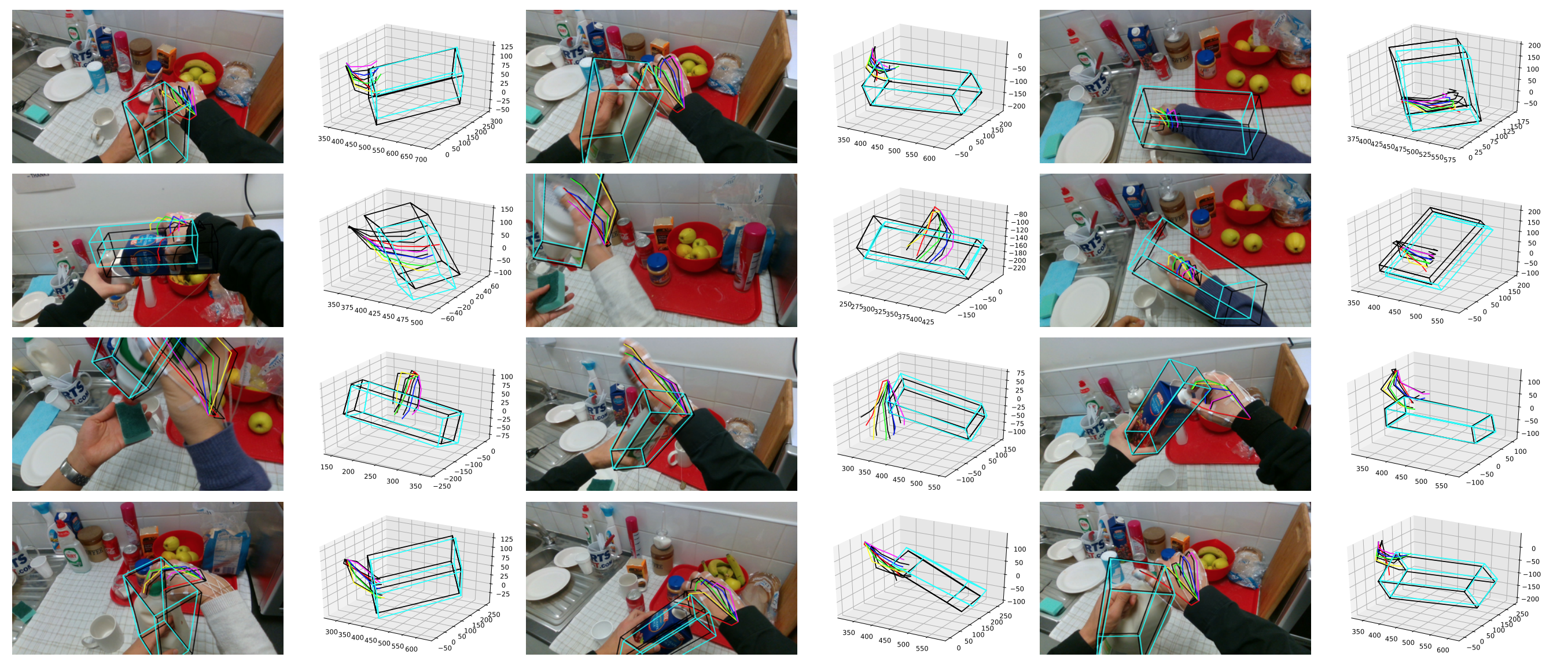
The goal of Hand-Object Pose Estimation (HOPE) is to jointly estimate the poses of both the hand and a handled object. Our HOPE-Net model can estimate the 2D and 3D hand and object poses in real-time, given a single image.
[papersandpresentations proj=egovision:hopenet]
Architecture
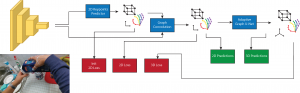
The architecture of HOPE-Net. The model starts with ResNet as the image encoder and for predicting the initial 2D coordinates
of the joints and object vertices. The coordinates concatenated with the image features used as the features of the input graph of a 3 layered graph convolution to use the power of neighbors features to estimate the better 2D pose. Finally the 2D coordinates predicted in the previous step are passed to our Adaptive Graph U-Net to find the 3D coordinates of the hand and object.

A schematic of our Adaptive Graph U-Net architecture, which is used to estimate 3D coordinates from 2D coordinates. In each of the pooling layers, we roughly cut the number of nodes in half, while in each unpooling layer, we double the number of nodes in the graph. The red arrows in the image are the skip layer features which are passed to the decoder to be concatenated with the unpooled features.
Downloads
Example Videos
Acknowledgements
This work was supported by the National Science Foundation (CAREER IIS-1253549) and the IU Office of the Vice Provost for Research, the College of Arts and Sciences, and the School of Informatics, Computing, and Engineering through the Emerging Areas of Research Project “Learning: Brains, Machines, and Children.”