Sven Bambach, Stefan Lee, David Crandall, Chen Yu
Abstract
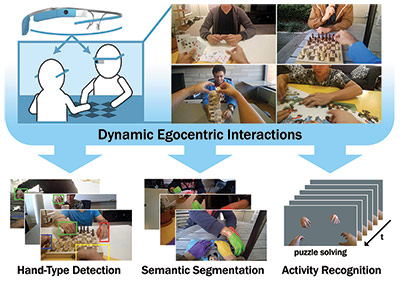
We present a CNN-based technique for detecting, identifying, and segmenting hands in egocentric video that includes multiple people interacting with each other. To illustrate one specific application, we show that hand segments alone can be used for accurate activity recognition.
Hands appear very often in egocentric video, and their appearance and pose give important cues about what people are doing and what they are paying attention to. But existing work in hand detection has made strong assumptions that work well in only simple scenarios, such as with limited interaction with other people or in lab settings. We develop methods to locate and distinguish between hands in egocentric video using strong appearance models with Convolutional Neural Networks, and introduce a simple candidate region generation approach that outperforms existing techniques at a fraction of the computational cost. We show how these high-quality bounding boxes can be used to create accurate pixelwise hand regions, and as an application, we investigate the extent to which hand segmentation alone can distinguish between different activities. We evaluate these techniques on a new dataset of 48 first-person videos (along with pixel-level ground truth for over 15,000 hand instances) of people interacting in realistic environments.
Dataset

Visualizations of our dataset and ground truth annotations. Left: Ground truth hand segmentation masks superimposed on sample frames from the dataset, where colors indicate the different hand types. Right: A random subset of cropped hands according to ground truth segmentations.
The EgoHands dataset contains 48 Google Glass videos of complex, first-person interactions between two people. The main intention of this dataset is to enable better, data-driven approaches to understanding hands in first-person computer vision. The dataset offers
- high quality, pixel-level segmentations of hands
- the possibility to semantically distinguish between the observer’s hands and someone else’s hands, as well as left and right hands
- virtually unconstrained hand poses as actors freely engage in a set of joint activities lots of data with 15,053 ground-truth labeled hands
We provide the entire EgoHands dataset online under vision.soic.indiana.edu/egohands!
Caffe Models
New! We provide our trained caffe models for egocentric hand classification/detection online. Both models take input via caffe’s window data layer. The first network classifies windows between hands and background, while the second network classifies windows between background and four different semantic hand types (own left/right hand and other left/right hand). Both networks are trained with the “main split” training data from our dataset.
- Hand classification/detection network: Prototxt File | Caffemodel File
- Hand-type classification/detection Network: Prototxt File | Caffemodel File
Window Proposal Code
New! We now provide MATLAB code for the window proposal method as discussed in Section 4.1 of the paper. If you also download the dataset from our dataset website, the provided code will learn sampling and skin-color parameters based on the training videos, as well as demonstrate how to apply the proposal method for unseen frames from the test videos. Simply download the file below and unzip it into the same directory as the dataset.
- Download: window_proposals.tar.gz
[papersandpresentations proj=”egovision:egohands”]
Acknowledgements
 |
 |
||||
| National Science Foundation |
National Institutes of Health |
Nvidia | Lilly Endowment | IU Data to Insight Center |