Zehua Zhang, Sven Bambach, David Crandall, Yu Chen
(This site is still under construction! More contents will be added in the future!)
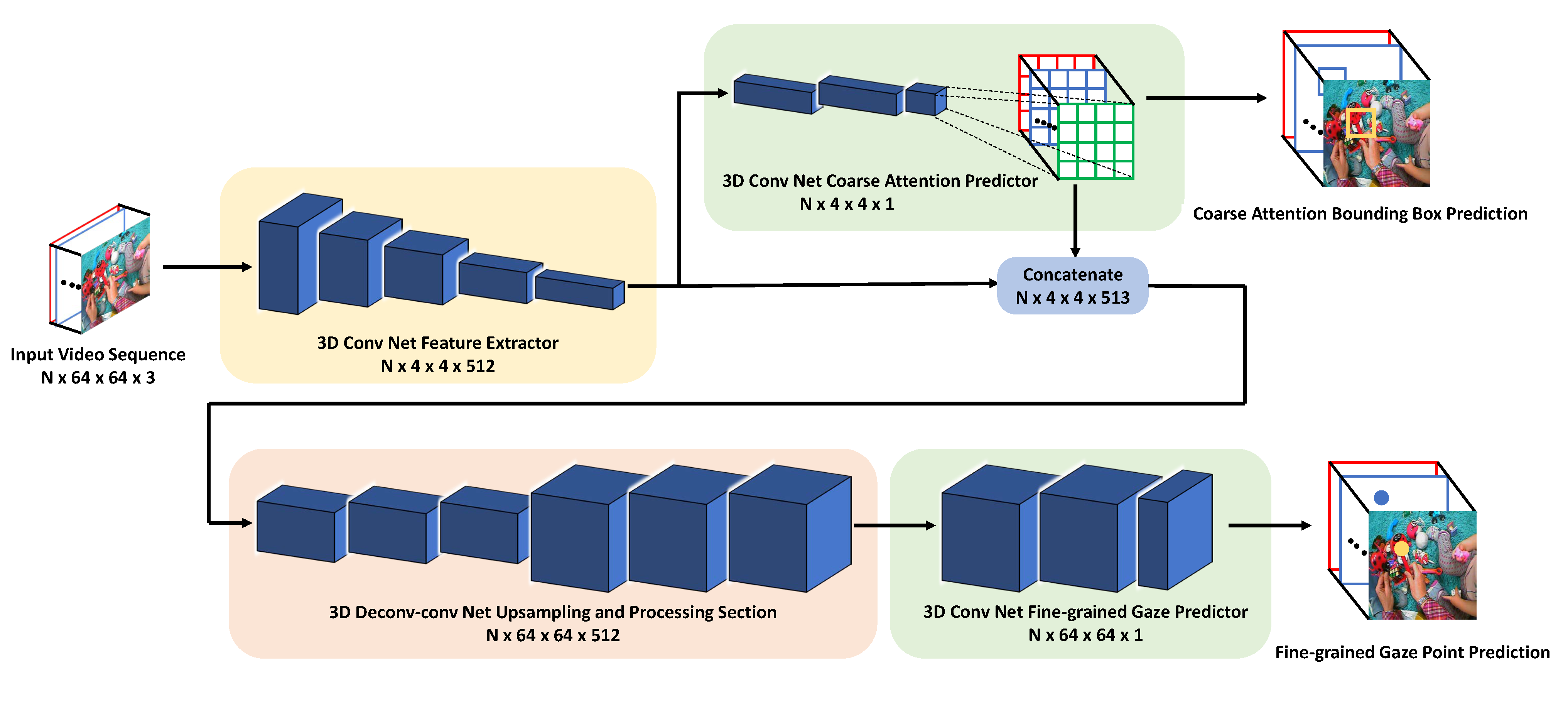
Figure 1: The architecture of our proposed two-stage 3D FCN model for eye gaze prediction. The number below each part indicates the output dimension of this part, where N is the length of the input video sequence.

Figure 2: Example results of our model. Frames in the first row are from the OST dataset. Frames from the second row to the last row are from the ATT dataset. The big red cross indicates the ground truth gaze point, the little green cross indicates the gaze point prediction, and the blue bounding box indicates the coarse attention cell prediction.
Here is a short video of visualization of the results. We removed the bounding box visualization and the big blue cross is now our predicted eye gaze while the big red cross still indicates the ground truth.
This video below shows an interesting sequence where the ground truth is not reasonable due to calibration error of the eye tracker. However, our model predicts reasonable eye gaze points here.
Detailed architecture of each module of our model:
1. Feature Extractor:
# 1st layer group
x = Conv3D(64, (tempConvSize, 3, 3), kernel_regularizer=l2(regularizer),
padding='same', name='current_conv1')(currentFrames)
x = BatchNormalization()(x)
x = Activation('relu')(x)
x = MaxPooling3D(pool_size=(1, 2, 2), strides=(1, 2, 2),
padding='valid', name='current_pool1')(x)
# 2nd layer group
x = Conv3D(128, (tempConvSize, 3, 3), kernel_regularizer=l2(regularizer),
padding='same', name='current_conv2')(x)
x = BatchNormalization()(x)
x = Activation('relu')(x)
x = MaxPooling3D(pool_size=(1, 2, 2), strides=(1, 2, 2),
padding='valid', name='current_pool2')(x)
# 3rd layer group
x = Conv3D(256, (tempConvSize, 3, 3), kernel_regularizer=l2(regularizer),
padding='same', name='current_conv3a')(x)
x = BatchNormalization()(x)
x = Activation('relu')(x)
x = Conv3D(256, (tempConvSize, 3, 3), kernel_regularizer=l2(regularizer),
padding='same', name='current_conv3b')(x)
x = BatchNormalization()(x)
x = Activation('relu')(x)
x = MaxPooling3D(pool_size=(1, 2, 2), strides=(1, 2, 2),
padding='valid', name='current_pool3')(x)
# 4th layer group
x = Conv3D(512, (tempConvSize, 3, 3), kernel_regularizer=l2(regularizer),
padding='same', name='current_conv4a')(x)
x = BatchNormalization()(x)
x = Activation('relu')(x)
x = Conv3D(512, (tempConvSize, 3, 3), kernel_regularizer=l2(regularizer),
padding='same', name='current_conv4b')(x)
x = BatchNormalization()(x)
x = Activation('relu')(x)
x = MaxPooling3D(pool_size=(1, 2, 2), strides=(1, 2, 2),
padding='valid', name='current_pool4')(x)
# 5th layer group
x = Conv3D(512, (tempConvSize, 3, 3), kernel_regularizer=l2(regularizer),
padding='same', name='current_conv5a')(x)
x = BatchNormalization()(x)
x = Activation('relu')(x)
x = Conv3D(512, (tempConvSize, 3, 3), kernel_regularizer=l2(regularizer),
padding='same', name='current_conv5b')(x)
x = BatchNormalization()(x)
exFeat = Activation('relu')(x)
2. Coarse Attention Predictor
x = Conv3D(512, (3, 3, 3), kernel_regularizer=l2(regularizer),
padding='same', name='current_conv6a')(exFeat)
x = BatchNormalization()(x)
x = Activation('relu')(x)
x = Conv3D(512, (1, 1, 1), kernel_regularizer=l2(regularizer),
padding='same', name='current_conv6b')(x)
x = BatchNormalization()(x)
x = Activation('relu')(x)
x = Conv3D(1, (1, 1, 1), kernel_regularizer=l2(regularizer),
padding='same', name='current_conv6c')(x)
x = BatchNormalization()(x)
cap = Activation('linear')(x)
3. Upsampling and Processing Section
x = Concatenate()([exFeat, cap])
x = Conv3DTranspose(512, (1, 4, 4), strides=(1, 4, 4), padding='valid', name='current_deconv_1')(x)
x = BatchNormalization()(x)
x = Activation('relu')(x)
x = Conv3D(512, (3, 3, 3), kernel_regularizer=l2(regularizer),
padding='same', name='current_conv7a')(x)
x = BatchNormalization()(x)
x = Activation('relu')(x)
x = Conv3D(512, (3, 3, 3), kernel_regularizer=l2(regularizer),
padding='same', name='current_conv7b')(x)
x = BatchNormalization()(x)
x = Activation('relu')(x)
x = Conv3DTranspose(512, (1, 4, 4), strides=(1, 4, 4), padding='valid', name='current_deconv_2')(x)
x = BatchNormalization()(x)
x = Activation('relu')(x)
x = Conv3D(512, (3, 3, 3), kernel_regularizer=l2(regularizer),
padding='same', name='current_conv8a')(x)
x = BatchNormalization()(x)
x = Activation('relu')(x)
x = Conv3D(512, (3, 3, 3), kernel_regularizer=l2(regularizer),
padding='same', name='current_conv8b')(x)
x = BatchNormalization()(x)
x = Activation('relu')(x)
4. Fine-grained Gaze Predictor
x = Conv3D(512, (1, 1, 1), kernel_regularizer=l2(regularizer),
padding='same', name='current_conv11a')(x)
x = BatchNormalization()(x)
x = Activation('relu')(x)
x = Conv3D(1, (1, 1, 1), kernel_regularizer=l2(regularizer),
padding='same', name='current_conv11b')(x)
x = BatchNormalization()(x)
fgp = Activation('linear')(x)
Our Adults, Toddlers and Toys (ATT) dataset
[papersandpresentations proj=egovision:deepgaze]
Downloads
- Poster
- Slides
- Full code will be available once we finish cleaning it
- ATT Dataset: Due to children privacy and human ethics, we are not able to publish it on the Internet. We are trying our best to make part of it available in the future. If you are interested in conducting research on this dataset, please contact the authors at zehzhang@indiana.edu.
Acknowledgements
This work was supported by the National Science Foundation (CAREER IIS-1253549) and the National Institutes of Health (R01 HD074601, R21 EY017843), and the IU Office of the Vice Provost for Research, the College of Arts and Sciences, and the School of Informatics, Computing, and Engineering through the Emerging Areas of Research Project “Learning: Brains, Machines, and Children.” We would like to thank Drew Abney, Esther Chen, Steven Elmlinger, Seth Foster, Laura Sloane, Catalina Suarez, Charlene Tay, Yayun Zhang for helping with the collection of the first-person toy play dataset, and Shujon Naha and Satoshi Tsutsui for helpful discussions.