The PR-AADB test set is a dataset for robustness evaluation for personalized image aesthetics assessment. It is a relabeling of the Aesthetics Attribute Dataset published in 2016 by Shu Kong et al.
The dataset, and our analysis, is described in our paper “Correct for Whom? Subjectivity and the Evaluation of Personalized Image Aesthetics Assessment Models”
Abstract: The problem of image aesthetic quality assessment is surprisingly difficult to define precisely. Most early work attempted to estimate the average aesthetic rating of a group of observers, while some recent work has shifted to an approach based on few-shot personalization. In this paper, we connect few-shot personalization, via Immanuel Kant’s concept of disinterested judgment, to an argument from feminist aesthetics about the biased tendencies of objective standards for subjective pleasures. To empirically investigate this philosophical debate, we introduce PR-AADB, a relabeling of the existing AADB dataset with labels for pairs of images, and measure how well the existing ground truth predicts our new pairwise labels. We find, consistent with the feminist critique, that both the existing ground truth and few-shot personalized predictions represent some users’ preferences significantly better than others, but that it is difficult to predict when and for whom the existing ground truth will be correct. We thus advise against using benchmark datasets to evaluate models for personalized IAQA, and recommend caution when attempting to account for subjective difference using machine learning more generally.
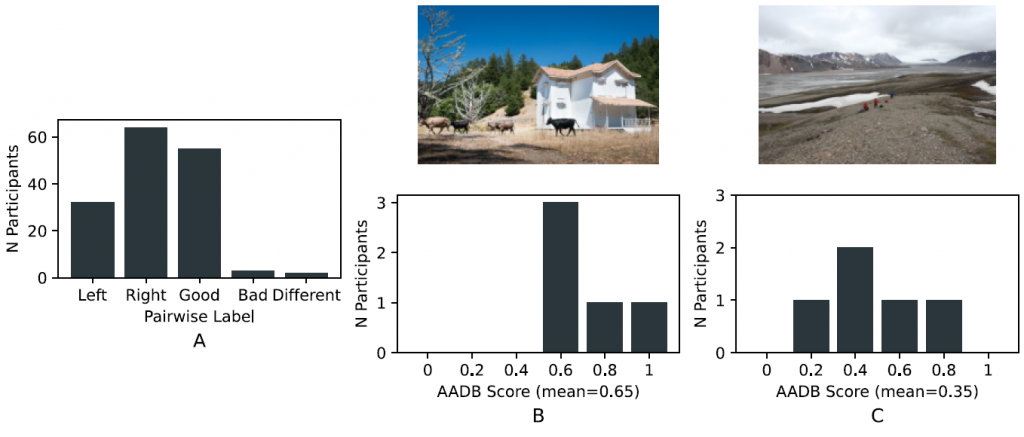
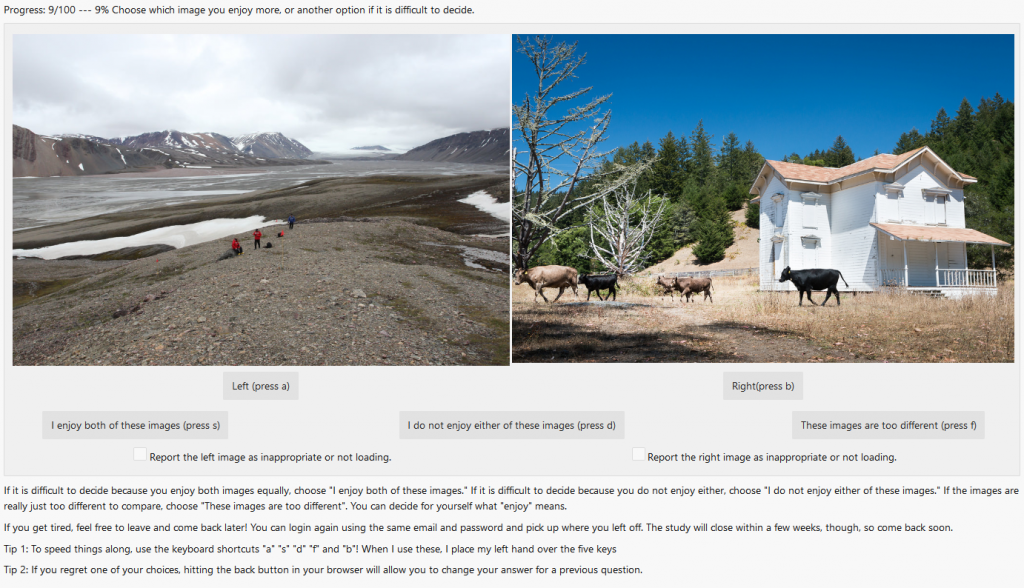
The data is relabeled in a pairwise manner, with pairs corresponding to relative preference for pairs of images. Each participant labeled the same 20 “common” image pairs shown to all participants and more “unique” image pairs (usually either 80 or 160) shown to only that person. Participants were asked “Choose which image you enjoy more, or another option if it is difficult to decide” and shown five labeling options:
- Left
- Right
- I enjoy both of these images
- I do not enjoy either of these images
- These images are too different
In the data zip file, there are three CSV files:
participant_data.csvcontains the survey data for each participant, with identifying information removed.labels.csvcontains the participant id, image ids, image paths and user-provided label for each labeled image pair. The label is encoded as an integer between 1 and 5 corresponding to the five options described above, except 1 corresponds toimage_aand 2 corresponds toimage_b. The image paths use the same format as the original AADB dataset.all_data.csvcontains the same information joined together in one spreadsheet.
Along with the collected image labels, we also provide the source code for our labeling interface. We recommend re-using our methodology to collect specific labels with your target user population and image domain, rather than evaluate on standardized aesthetic quality assessment benchmarks.
The interface is a Django web application with a sqlite database. It is currently configured to use manage.py commands to load the list of images, list of image pairs and list of users from existing CSV files, but could be easily extended to handle user registration or image uploading via a web form.
If you have any questions/comments/concerns about this material please send an email to Sam Goree, sgoree [at] iu [dot] edu